
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 패스트파이브
- 가든웨딩
- innernavigation
- 너무 어렵다
- parentfragment
- 안드로이드
- 사무실
- 백준
- 후기
- media3
- 스택
- 중첩네비게이션
- media3 transformer
- 공유오피스
- 자바
- rxandroid
- 더베일리하우스 삼성점
- Stack
- 코틀린
- fragmentcontainer
- 파이썬
- SAA
- 패파
- Kotlin
- 재밌긴함
- 아키텍쳐
- Android
- 알고리즘
- 내부프레그먼트
- MVVM
Archives
삽질도사
[파이썬] python groupby,loc,iloc 헷갈리는 거 위주로 적어놈. 본문
반응형
원하는 내용을 뽑아올 때 헷갈리기 쉬운거 후딱 정리들어갑니다.
원래의 자료는 Name,Team,Number,Position,Age 등등 열이 많습니다.
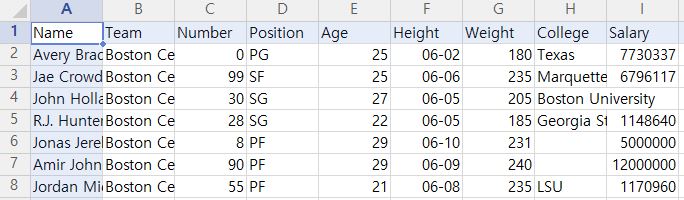
data = pd.read_csv('nba.csv',sep=',') #데이터 읽음
print(data[['Name','Age']].head(3)) # 대괄호가 2개니까 주의!!
print(type(data[['Name','Age']])) #dataframe 타입
print(data.loc[:,['Name','Age']]) #loc을 통해서 뽑아옴
print(type(data.loc[:,['Name']])) #dataframe 타입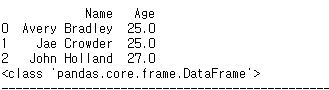
print(data.iloc[:][['Name','Age']].head(3)) #i번째 행을 가져와서 'Name','Age'열을 따로 뽑아라
print(type(data.iloc[:][['Name','Age']])) #dataframe 타입
print(type(data.iloc[:]['Name'])) #series 타입 !!
따라서 정리하자면,
print(type(data.iloc[0])) # 하나의 행만 가져오는 것 -> series
print(type(data.iloc[:])) # 여러개의 행을 가져오는 것 -> dataframe
참고로 하나의 열을 가져올 때 대괄호의 갯수에 따라 가져오는 자료형이 달라집니다.
print(type(data['Salary']))
print(type(data[['Salary']]))
이번엔 groupby에 대해서 헷갈리는 부분/팁을 정리하겠습니다.
당연하지만 바로 위에서 말했던 것처럼 대괄호 갯수에 따라 groupby도 반환하는게 달라집니다
grouped2 = data['Salary'].groupby(data['Team']) # Team별로 Salary 대괄호 1개
print(grouped2.mean().head(3)) #그것의 평균
print(type(grouped2.mean())) #series
print('-------------------------------------------------------------------------------')
grouped2 = data[['Salary']].groupby(data['Team']) # Team별로 Salary 대괄호 2개 df이므로 groupby에 옵션을 추가할 수 있다는 차이점이 존재함.
print(grouped2.mean().head(3))
print(type(grouped2.mean())) #dataframe
이번엔 groupby를 통해서 자료를 읽어왔을 때, 겪는 상황입니다. 일반적으로 가져와서 데이터를 정리하면 편할텐데 그냥 가져오면 첫 번째 열이 index가 되어버려서 나중에 색인하기가 힘든 상황을 겪었습니다.
따라서 as_index =0 이라는 옵션을 통해서 해결했습니다.
grouped = data.groupby(data['Team']).mean() #그냥 들고오면 첫 열이 index가 됌
print(grouped.head(3))
print('-------------------------------------------------------------------------------')
grouped = data.groupby(data['Team'],as_index=0).mean() ##as_index = 0을 사용해서 index를 숫자로 가져옴
print(grouped.head(3))
아..헷갈려..
반응형
'DB or 파이썬' 카테고리의 다른 글
| [파이썬] python 피봇(pivot)사용하기, 인덱스 만들기(짧음) (0) | 2021.10.29 |
|---|---|
| [파이썬] python 그래프 한글 깨져서 나올 때, 한글작업하기(간단) (0) | 2021.10.28 |
| [파이썬] python 공공 데이터를 읽어올 때, 액셀처럼 여러 항목을 포함하는 열은 어떻게 표현될까? (짧음) (0) | 2021.10.28 |
| [파이썬] python 그래프(도표)에 숫자가 뒤죽박죽 섞여있는 경우 (0) | 2021.10.28 |
| [파이썬] pandas로 파일/자료 깔끔하게 읽어오기(short) (0) | 2021.10.15 |
'DB or 파이썬' Related Articles
more



